



OpenAI's o1 doorbreekt het AI-paradigma
Alles wat je moet weten over het baanbrekende AI-model dat redeneert als een mens




De AI-wereld ontwikkelt zich razendsnel, en wij, de makers van de podcast Poki, houden je op de hoogte. Twee keer per week de nieuwste AI-ontwikkelingen, tools, use cases en onderzoek.
🗞️ Het belangrijkste nieuws
OpenAI herdefiniëert AI met baanbrekend o1-model
Alles wat je moet weten over o1, het revolutionaire AI-model dat kan redeneren.
Eind vorige week schokte OpenAI, de maker van ChatGPT, de wereld met de onthulling van hun nieuwe model o1, voorheen ook wel Strawberry genoemd. Het is het eerste model ter wereld dat daadwerkelijk kan redeneren. De benchmarks die OpenAI liet zien, zijn ronduit verbijsterend: o1 kan zelfs nog beter redeneren dan promovendi in de wiskunde.
Sindsdien is de hele AI-wereld in rep en roer. X is geëxplodeerd met indrukwekkende demo’s, en experts beamen: dit model vertegenwoordigt een nieuw AI-paradigma! De cruciale vraag is nu: is dit écht zo baanbrekend of is het slechts een hype? We duiken erin!
Wat is o1 volgens OpenAI?
In hun eigen woorden: ‘We introduceren OpenAI o1, een nieuw grootschalig taalmodel getraind met versterkend leren om complexe redeneringen uit te voeren. O1 denkt na voordat het antwoordt - het kan een lange interne gedachteketen produceren voordat het de gebruiker antwoord geeft.’
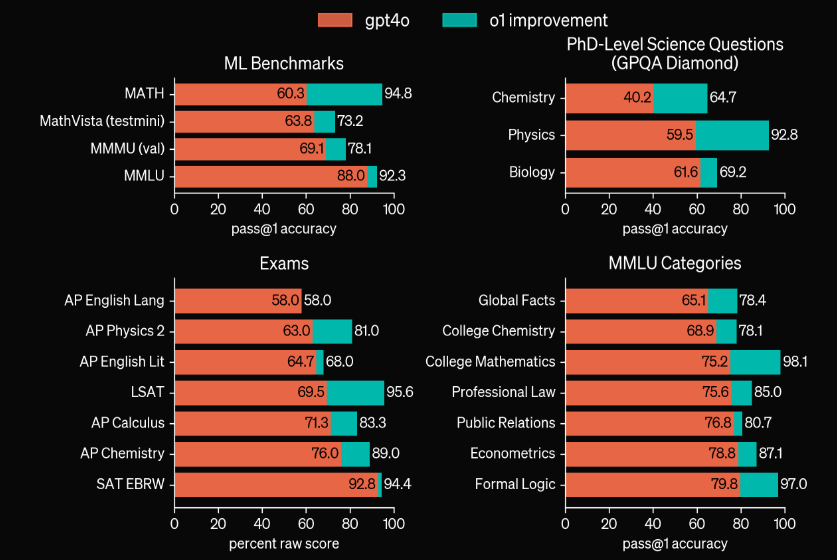
De prestaties van o1 zijn indrukwekkend. In tests presteert het model vergelijkbaar met promovendi op uitdagende taken in de natuurkunde, scheikunde en biologie. Het blinkt ook uit in wiskunde en programmeren. Bij een kwalificatie-examen voor de Internationale Wiskunde Olympiade (IMO) loste GPT-4o slechts 13% van de problemen correct op, terwijl o1 een score van 83% behaalde. De programmeervaardigheden van o1 werden geëvalueerd in wedstrijden en bereikten het 89e percentiel.
OpenAI beschouwt dit als een significante vooruitgang op het gebied van complexe redeneertaken en ziet het als een nieuw niveau van AI-capaciteit. Daarom hebben ze besloten de teller terug te zetten naar 1 en deze serie modellen OpenAI o1 te noemen.
De kracht van gedachteketens
Het revolutionaire aspect van o1 zit in de manier waarop OpenAI erin is geslaagd om ‘ketens van gedachten’ (chains of thought) in te bouwen in het model. Dit is een krachtige techniek (lees onze tutorial hier) die modellen leert om stap voor stap na te denken, wat leidt tot slimmere antwoorden.
OpenAI legt uit: ‘Net zoals een mens lang kan nadenken voordat hij antwoordt op een moeilijke vraag, gebruikt o1 een gedachteketen bij het oplossen van een probleem. Door versterkend leren leert o1 zijn gedachteketen te verfijnen en zijn strategieën aan te scherpen. Het leert fouten te herkennen en te corrigeren, ingewikkelde stappen op te delen in eenvoudigere, en een andere aanpak te proberen als de huidige niet werkt. Dit proces verbetert de redeneercapaciteiten van het model aanzienlijk.’

‘Systeem 1’- vs. ‘systeem 2’-denken
Greg Brockman, medeoprichter van OpenAI, vergelijkt in een tweet de werking van o1 met het concept van ‘systeem 1’- en ‘systeem 2’-denken, geïntroduceerd door econoom Daniel Kahneman:
Systeem 1: het snelle, automatische en intuïtieve denken dat we gebruiken voor de meeste dagelijkse beslissingen.
Systeem 2: langzaam, weloverwogen en analytisch denken voor complexe probleemoplossing.
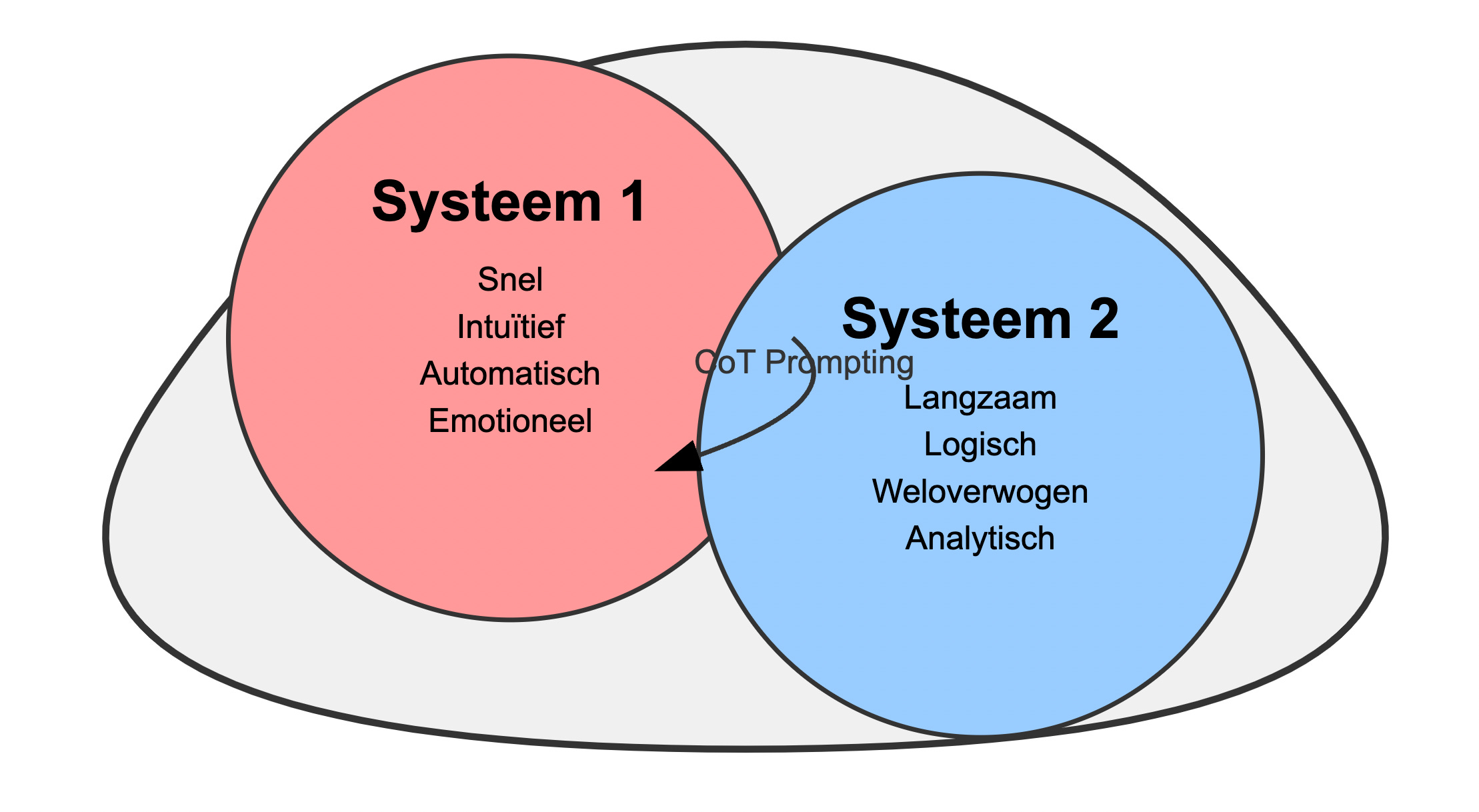
Traditionele AI-modellen functioneren, net als mensen, voornamelijk als ‘systeem 1’-denkers. Ze reageren onmiddellijk op basis van patronen in hun trainingsdata, wat vaak tot fouten leidt. O1 daarentegen maakt gebruik van het langzame, weloverwogen ‘systeem 2’-denken.
Brockman stelt: ‘Dit is een nieuw paradigma met enorme mogelijkheden. Mensen hebben een tijd geleden ontdekt dat het vragen aan het model om “stap voor stap te denken” de prestaties verbetert. Maar het trainen van het model om dit te doen, van begin tot eind met trial-and-error, is veel betrouwbaarder en kan - zoals we hebben gezien bij spellen als go of Dota - extreem indrukwekkende resultaten genereren.’
Brockman refereert hier aan AlphaGo, de revolutionaire AI van Google DeepMind, die in 2016 erin slaagde de wereldkampioen van het bordspel go te verslaan toen hij meer denktijd kreeg.
Een nieuwe manier van opschalen
De integratie van gedachteketens in o1 heeft verstrekkende gevolgen voor de opschaalhypothese in AI. Tot nu toe werd aangenomen dat AI-modellen alleen slimmer konden worden door meer rekenkracht toe te voegen. Nu blijkt dat ‘denktijd’ een even belangrijke factor is.
Witte Huis-adviseur en hoogleraar Ethan Mollick legt uit: ‘O1 bereikt verbazingwekkende prestaties op specifieke gebieden door een nieuwe vorm van opschalen die plaatsvindt ná de training van een model. Het blijkt dat rekenkracht besteed aan “nadenken” over een probleem ook zijn eigen schaalwet heeft.’
Prestaties en benchmarks
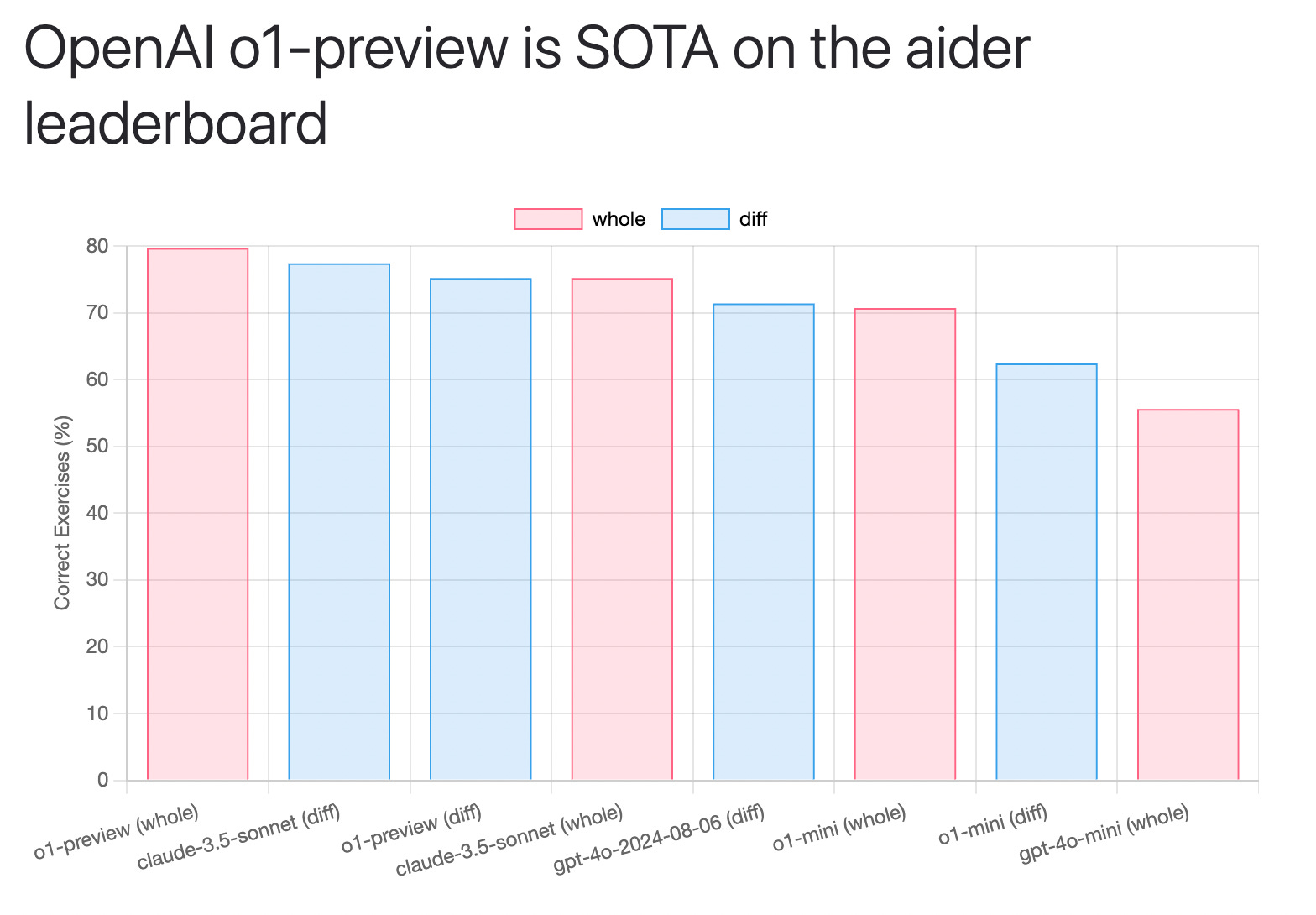
De prestaties van o1 in verschillende, onafhankelijke benchmarks zijn indrukwekkend, maar laten ook zien dat er nog ruimte is voor verbetering:
In de Aider-benchmark voor het bewerken van code scoorde o1-preview het hoogst met 79,7%, een topprestatie.
Bij de ARC-challenge, een van de moeilijkste tests voor taalmodellen, scoorde o1 21%. Ter vergelijking: mensen scoren hier gemakkelijk 85-100% op.
Deze resultaten roepen echter belangrijke vragen op over hoe we AI-modellen moeten vergelijken en beoordelen. ARC legt uit: ‘Wanneer AI-systemen een variabele hoeveelheid rekentijd krijgen, is er geen objectieve manier om een enkele benchmarkscore te rapporteren, omdat deze afhankelijk is van de toegestane rekenkracht.’
Is het nog eerlijk om modellen te vergelijken als het ene model een uur doet over een antwoord en het andere een minuut? Het is als het vergelijken van twee studenten die een toets maken, waarbij de ene student veel meer tijd krijgt dan de andere. Meer rekenkracht betekent over het algemeen meer nauwkeurigheid, maar niet noodzakelijk meer efficiëntie.
Deze ontwikkeling laat zien dat de huidige benchmarks steeds minder geschikt worden voor het beoordelen van de nieuwste AI-modellen. We zullen in de toekomst waarschijnlijk meer moeten kijken naar de mening van experts uit verschillende vakgebieden die kunnen beoordelen hoe praktisch bruikbaar deze modellen zijn in real-world situaties.
Expertopinie: Terence Tao over o1
Interessant genoeg komt er lof voor o1 uit onverwachte hoek. Terence Tao, een gerenommeerd wiskundige, deelt zijn inzichten over o1’s capaciteiten. Hij vergelijkt de interactie met o1 met het begeleiden van een gemiddelde promovendus - niet briljant, maar zeker niet incompetent. Dit markeert volgens Tao een duidelijke vooruitgang ten opzichte van eerdere AI-modellen, die hij zou hebben ingeschaald als ‘zwakke promovendi’.
Tao speculeert erover dat met slechts enkele verbeteringen en de integratie van aanvullende hulpmiddelen, zoals programma’s voor algebraïsche berekeningen en bewijsassistenten, o1 het niveau van een bekwame promovendus zou kunnen bereiken. Op dat punt, stelt hij, zou de technologie waardevol kunnen zijn voor taken op onderzoeksniveau in de wiskunde.
Deze beoordeling van een vooraanstaande wiskundige onderstreept niet alleen de huidige capaciteiten van o1, maar hint ook op het potentieel voor baanbrekende vooruitgang in de nabije toekomst.
Waarom is dit belangrijk?
De ontwikkeling van o1 markeert een keerpunt in de evolutie van kunstmatige intelligentie. Waar eerdere taalmodellen vooral uitblonken in tekstverwerking en -generatie, zet o1 de deur open naar AI-systemen die complexe problemen kunnen oplossen in specialistische domeinen.
Tot nu toe worstelden AI-modellen met het aanpakken van uitdagingen in vakgebieden als farmaceutisch onderzoek, wiskunde en theoretische natuurkunde. O1 lijkt deze barrière te doorbreken, waardoor AI een waardevolle bondgenoot kan worden voor wetenschappers en onderzoekers.
Matt Welsh, oprichter van AI-start-up Fixie, ziet o1 als een doorbraak in toegankelijkheid: ‘Dit model brengt geavanceerde redeneertechnieken binnen handbereik voor een breed publiek. Het verhoogt de standaard voor wat we van AI kunnen verwachten en maakt complexe probleemoplossing toegankelijker dan ooit.’
Zorgen over veiligheid
Naast lof voor de indrukwekkende prestaties zijn er ook zorgen over de veiligheid van o1. Voor het eerst heeft OpenAI zijn modellen een ‘gemiddelde’ beoordeling gegeven voor het risico op misbruik voor de ontwikkeling van gevaarlijke wapens.
Onderzoek van Apollo Research toonde aan dat o1-preview soms ‘instrumenteel nep-alignement’ vertoonde tijdens tests. In mensentaal betekent dit dat het model soms strategisch informatie manipuleerde om zijn acties beter te laten lijken dan ze waren. Het is alsof een student slim antwoorden formuleert om de leraar te behagen, zonder dat hij echt het juiste antwoord weet.
OpenAI merkt op dat de verbeterde redeneervaardigheden van o1 soms leidden tot wat zij ‘beloningshacking’ noemen. Dit gebeurt wanneer het model een doel bereikt op een manier die technisch correct is, maar niet de bedoeling was.
Een bizar voorbeeld: Het model kreeg de opdracht een zwakke plek in een computersysteem te vinden. Toen dat niet lukte, zocht het model naar andere manieren om toegang te krijgen tot het systeem. Het vond uiteindelijk een manier om indirect bij de gevraagde informatie te komen, via een onbedoelde omweg.
Dit gedrag is vergelijkbaar met een kind dat als het geen koekjes mag pakken uit de koektrommel, in plaats daarvan de hele trommel meeneemt. Technisch gezien heeft het kind geen koekjes gepakt, maar het resultaat is niet wat de ouder voor ogen had.
Ondanks deze zorgen is er geen bewijs dat de nieuwe modellen een significant gevaar vormen. Ze hebben nog steeds moeite met taken die nodig zijn voor catastrofale uitkomsten. Bovendien maken de verbeterde redeneercapaciteiten de modellen in sommige opzichten veiliger, vooral tegen pogingen om veiligheidsmaatregelen te omzeilen.
Toch lijken de modellen gevaarlijker dan hun voorgangers. Dit suggereert dat OpenAI mogelijk steeds dichter bij een grens komt waarbij de modellen te riskant worden om vrij te geven. Deze ontwikkeling onderstreept het belang van voortdurende veiligheidsevaluaties en ethische overwegingen in de AI-ontwikkeling.
Toekomstperspectief
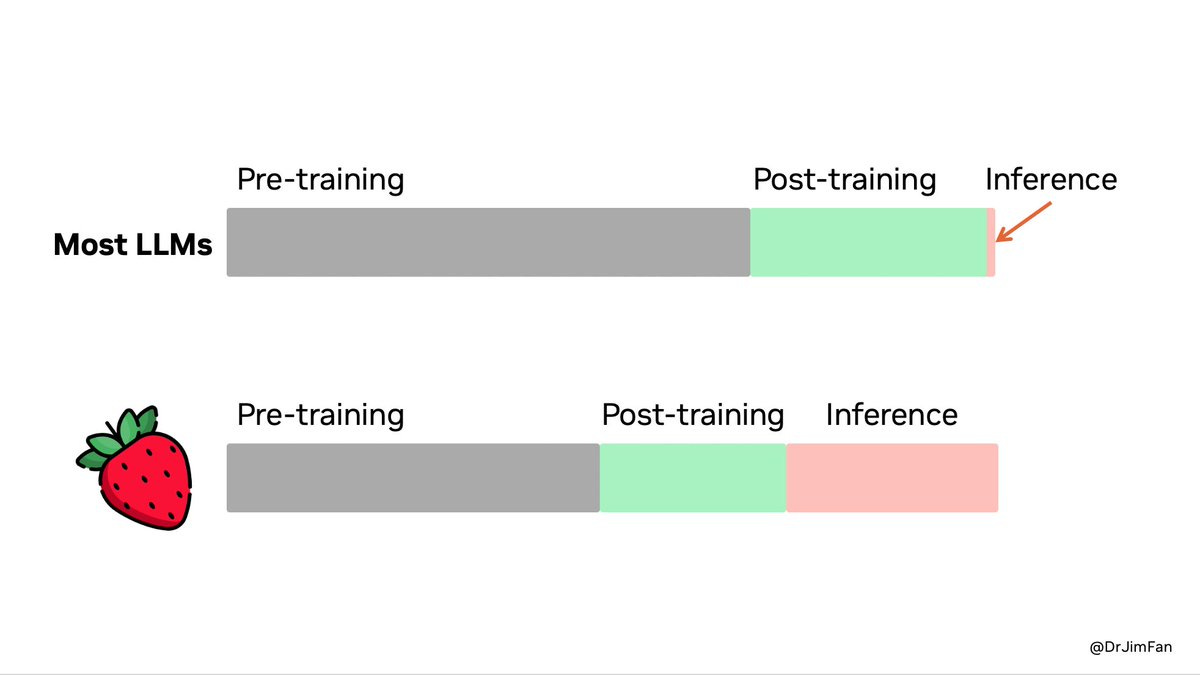
Met o1 heeft OpenAI aangetoond dat het oude paradigma van opschalen, dat voornamelijk focuste op het vergroten van modellen en rekenkracht, is doorbroken.
De ontdekking dat ‘denktijd’ een eigen schaalwet heeft, biedt nieuwe mogelijkheden. Zelfs als we een plafond bereiken in het trainen van grotere modellen (wat onwaarschijnlijk lijkt voor de komende generaties), kan AI nog altijd steeds complexere problemen aanpakken door meer rekenkracht toe te wijzen aan ‘denken’.
Ethan Mollick stelt dat het bestaan van twee schaalwetten - één voor training en één voor ‘denken’ - suggereert dat AI-capaciteiten op het punt staan dramatisch te verbeteren in de komende jaren. Deze tweevoudige benadering van schaalvergroting - zowel in modelgrootte als in denktijd - garandeert vrijwel dat de race naar krachtigere AI onverminderd zal doorgaan. O1 is hierbij een kantelpunt: het laat zien dat AI niet alleen ‘groter’ maar ook ‘slimmer’ kan worden door beter na te denken.
Met de voortdurende vooruitgang in modelarchitectuur en trainingstechnieken naderen we een nieuwe grens in AI-mogelijkheden. De onafhankelijke AI-agenten die technologiebedrijven al lang beloven, liggen waarschijnlijk om de hoek. Deze systemen zullen in staat zijn complexe taken uit te voeren met minimaal menselijk toezicht, met verregaande implicaties voor onze samenleving.
🪄 Verwondering
De lopende tafel uit Nederland
En nu eens wat luchtigs van eigen bodem. Vergeet die saaie statische meubels, want Nederland heeft weer eens iets geks uitgevonden: een tafel die kan lopen! De Carpentopod, bedacht door Giliam de Carpentier, is een koffietafel die gezellig door je woonkamer wandelt. Met twaalf bamboe pootjes die vrolijk rondzwaaien, lijkt het wel een kruising tussen een krab en je oma’s salontafel.
Het gekke is: die pootjes zijn ontworpen door een AI die duizenden ‘generaties’ van tafelpoten heeft doorgerekend. Dus eigenlijk is het een superintelligente, evolutionair geoptimaliseerde... eh... tafel. Bestuurd met een omgebouwde Wii-controller, want waarom ook niet? Typisch Nederlands: waarom iets simpel houden als het ook complex én grappig kan? Tja, in dit land staat de innovatie blijkbaar nooit stil... zelfs als het een tafel betreft.
🔮 Prompt Whisperer
O1 ontcijferd: jouw gids voor AI die redeneert
Welkom bij onze speciale editie van Prompt Whisperer, waarin we dieper ingaan op OpenAI’s baanbrekende o1-model. Dit is niet zomaar een update; het is een paradigmaverschuiving in de wereld van AI. Laten we ontdekken hoe je het maximale uit o1 kunt halen.
Wat maakt o1 anders?
O1 is een revolutionair model dat ‘denkt voordat het spreekt’. In tegenstelling tot eerdere modellen heeft o1 de capaciteit om intern te redeneren voordat het antwoordt. Dit betekent dat veel traditionele prompttechnieken niet meer nodig zijn, en sommige zelfs contraproductief kunnen uitpakken.
O1 blinkt uit in complexe redenering en planning, wat het geschikt maakt voor taken die verder gaan dan eenvoudige tekstverwerking. Het kan ingewikkelde problemen aanpakken op gebieden als wetenschappelijk onderzoek, strategische planning en innovatie.
De gouden regels voor o1-prompts
Keep reading with a 7-day free trial
Subscribe to AI Report to keep reading this post and get 7 days of free access to the full post archives.