



China aan zet: hoe DeepSeek de AI-wereld wakker schudt
PLUS: OpenAI’s Operator-agent is er, en draai zelf AI-modellen op je laptop voor maximale privacy




De AI-wereld ontwikkelt zich razendsnel, en wij, de makers van de podcast Poki, houden je op de hoogte. Twee keer per week de nieuwste AI-ontwikkelingen, tools, use cases en onderzoek.
🗞️ Het belangrijkste nieuws
OpenAI lanceert Operator, maar alle ogen zijn gericht op China
OpenAI bracht deze week groot nieuws: Operator, hun eerste AI-agent die zelfstandig taken op het web kan uitvoeren. Een mijlpaal die de headlines zou moeten domineren. Maar in plaats daarvan heeft iedereen het over een Chinese nieuwkomer. Zelfs de NOS, die zelden over AI-ontwikkelingen bericht, schrijft over DeepSeek.
Hoe kan het dat een opensourcemodel uit China de shine steelt van Silicon Valleys AI-kampioen? Toen we vorige week over DeepSeeks R1 schreven, voorspelden we al dat dit belangrijk zou worden. Maar de impact blijkt nog veel groter dan gedacht.
Wall Street raakte in paniek: beleggers in NVIDIA zagen hun aandelen met 16 procent kelderen, wat leidde tot een schokgolf, die meer dan een biljoen aan beurswaarde deed verdampen. Onze WhatsApp ontplofte met berichten van zelfs niet-tech-savvy ouders: ‘Heb je die app DeepSeek al geprobeerd? Is een AI uit China of zo. Echt heel slim!’
Maar wat betekent deze ontwikkeling écht, voorbij de headlines? We zijn er diep in gedoken om het grotere plaatje te schetsen.
OpenAI’s moment dat nooit kwam
Eerst nog even het nieuws dat OpenAI bracht te midden van deze storm: Operator, hun eerste AI-agent die zelfstandig taken op het web kan uitvoeren. De agent kan formulieren invullen, boodschappen bestellen en zelfs memes maken. Na maandenlange geruchten is hij nu beschikbaar voor pro-abonnees voor 200 dollar per maand (alleen in Amerika, voor nu). Dit had het gesprek van de week moeten zijn.
Maar de praktijk blijkt weerbarstiger. Het zit nog vol beperkingen: zo moet je constant toestemming geven voor elke stap, en veel websites hebben captcha’s die je handmatig moet invullen. OpenAI’s eigen veiligheidsrapport onthult dat Operator in zo’n 10 procent van de gevallen ‘onomkeerbare fouten kan maken, zoals e-mails naar de verkeerde ontvanger sturen’.
Kortom: het geeft een glimpje van de toekomst, maar als je je afvraagt of Operator al je baan kan automatiseren: het antwoord is een volmondig nee.
Het Spoetnik-moment van AI
Marc Andreessen, prominent investeerder in Silicon Valley, noemt DeepSeeks doorbraak ‘AI’s Spoetnik-moment’ – een verwijzing naar de schok die Amerika te verwerken kreeg toen de Sovjets als eerste een satelliet in een baan om de aarde brachten. Voor het eerst wordt Silicon Valley zo ondersteboven gezet door iets wat niet uit zijn eigen keuken komt.
De impact op de industrie is enorm. Meta heeft ‘war rooms’ opgezet om te analyseren hoe DeepSeek dit voor elkaar kreeg. Volgens The Information hebben directeur AI-infrastructuur Mathew Oldham en andere leiders hun zorgen geuit: Meta’s volgende vlaggenschip, Llama, zal niet kunnen concurreren met DeepSeek.
Eric Schmidt, voormalig Google-CEO, moest zijn voorspellingen drastisch bijstellen: ‘Ik dacht dat we een paar jaar voorlagen op China, maar ze hebben die voorsprong in de laatste zes maanden op een opmerkelijke manier ingelopen.’
Waarom iedereen er nu over praat
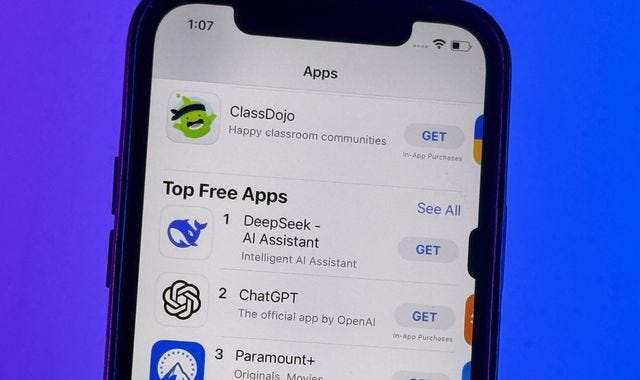
DeepSeek-R1 is in recordtijd de meest gedownloade app in Amerikaanse appstores geworden. Voor het eerst kan het grote publiek gratis gebruikmaken van een ‘redeneermodel’ dat net zo slim is als OpenAI’s o1 – waarvoor je nog steeds 20 euro per maand moet betalen.
‘De kwaliteit van de teksten voelt tien keer minder gerobotiseerd en heeft tien keer meer flair dan bij andere modellen,’ merkt tech-analist Jasmine Sun op. Een uniek aspect is dat gebruikers de gedachtestappen van het model kunnen volgen. Deze transparantie zorgt voor vertrouwen en maakt het ‘schattig’ en toegankelijk voor nieuwe gebruikers, ook al zit daarachter revolutionaire technologie verborgen.
De ironie van exportcontroles
Het fascinerendste aspect? Dit alles is mogelijk juist het gevolg van Amerikaanse pogingen om China’s AI-ontwikkeling af te remmen. ‘De exportbeperkingen waren bedoeld om de race te vertragen en Amerikaanse technologie in Amerika te houden,’ legt Perplexity-CEO Aravind Srivinas uit. ‘Maar het tegenovergestelde gebeurde. Noodzaak is de moeder van deze uitvinding – omdat ze workarounds moesten vinden, hebben ze iets veel efficiënters gebouwd.’
Waar Amerikaanse labs toegang hebben tot de nieuwste NVIDIA-chips, moet DeepSeek het doen met afgeschaalde H800-chips vanwege exportrestricties. Dylan Patel, een vooraanstaande AI-analist, schat dat ze mogelijk 50.000 chips gebruikten – een enorm aantal. Maar Kai-Fu Lee vertelde vorig jaar dat zijn team bij het vergelijkbare Chinese lab ZeroOne.ai een topmodel trainde op ‘slechts’ 2000 H100-GPU’s, ongeveer een tiende van wat de grootste Amerikaanse labs gebruiken.
Hoe DeepSeek het voor elkaar kreeg
In de media lees je vaak een te simpel verhaal: een Chinese start-up die met oude computers Silicon Valley verslaat. De werkelijkheid is genuanceerder.
DeepSeek-R1 bouwt voort op het eerdere model V3, dat al op GPT-4-niveau presteerde. Het is dus géén model gebouwd ‘from scratch’ voor 5 miljoen dollar. Hoe ze dat precies hebben gedaan, leggen ze uit in hun paper, in begrijpelijke taal:
In plaats van een compleet nieuw brood te bakken vanaf de basis-ingrediënten (meel, gist, water), kreeg DeepSeek een al behoorlijk goed voorgebakken brood (hun eerdere model V3), dat ze verder konden verfijnen. Onze Wietse stelt: ‘De kunst zat hem in hóé ze dit brood verder bakten.’
Waar OpenAI elk stapje in het bakproces nauwkeurig voorschrijft en controleert, koos DeepSeek voor een andere aanpak: ze lieten het model vrijer experimenteren om zelf de beste weg te vinden. Dit leidde tot verrassende resultaten – soms ‘denkt’ het model zelfs in andere talen dan Engels, alsof het zijn eigen recept schrijft.
De aanpak bestond uit vijf stappen:
Men nam het bestaande model en liet het leren van een klein aantal goede voorbeelden – veel minder dan normaal nodig is.
Reinforcement learning: men liet het model experimenteren en beloonde het wanneer het de juiste antwoorden vond (zoals een kok die verschillende technieken uitprobeert).
De beste resultaten werden verzameld en gebruikt als nieuwe voorbeelden.
Deze nieuwe kennis werd gecombineerd met wat het model al wist over schrijven en feiten.
Er vond een laatste ronde van experimenteren plaats om ervoor te zorgen dat het model zijn kennis breed kon toepassen.
Het resultaat? DeepSeek zegt dat ze 45 keer efficiënter werken dan de standaardmethoden. Ze doen dit door slimme trucs toe te passen: waar absolute precisie niet nodig is, gebruiken ze snellere, maar minder nauwkeurige berekeningen. Ook programmeren ze hun instructies zo dicht mogelijk bij de ‘taal’ van de chips zelf – vergelijk het met een kok die precies weet hoe zijn oven werkt en daar optimaal gebruik van maakt.
Deze efficiëntie heeft een cruciaal voordeel: je kunt kleinere versies van het model zelfs op je eigen computer draaien. Met een Mac Mini kun je al een kleinere versie van R1 lokaal gebruiken. Of: zoals deze inventieve gebruiker doet, met 7 Mac Mini’s en een Macbook heb je de volledige R1 aan het draaien. Het is misschien wat langzamer, maar voor wie privacy belangrijk is, is dit spectaculair. Want of je nu met ChatGPT of DeepSeek online praat, je data worden altijd naar hun servers gestuurd. Met een lokaal draaiend model blijven je gegevens volledig privé – een uitkomst voor bedrijven en individuen die hun data niet willen delen.
De alignmentparadox
Deze aanpak roept wel belangrijke vragen op over ‘alignment’ – hoe we ervoor zorgen dat AI-systemen zich gedragen zoals wij willen. Voorstanders van open source zien DeepSeeks transparantie als een voordeel: anders dan bij OpenAI’s gesloten modellen kunnen we precies zien hoe R1 redeneert.
Maar er is een keerzijde. DeepSeek heeft R1 geoptimaliseerd om de juiste antwoorden te geven, ongeacht hoe het daar komt. OpenAI besteedde juist veel energie aan het belonen van veilige denkstappen. R1 denkt soms zelfs in andere talen dan Engels – fascinerend, maar ook zorgwekkend.
Een voormalige Google DeepMind- en OpenAI-medewerker was nog directer toen hem werd gevraagd naar het veiligheidsplan na DeepSeek: ‘Er is geen plan.’
Een verschuiving van talent
DeepSeeks oorsprong is fascinerend: het ontstond als zijproject van High-Flyer, een hedgefonds. Dit illustreert een belangrijke verschuiving: waar briljante afgestudeerden vroeger naar de financiële sector trokken, kiezen ze nu steeds vaker voor AI-ontwikkeling.
Zoals ondernemer Arnaud Bertrand opmerkt: ‘China keek naar het Westen en zag hoe de financiële sector talent wegzoog van de echte economie. Je wilt dat je beste mensen waarde creëren, niet alleen extracten.’
Ook hun bedrijfscultuur is vernieuwend: waar Chinese techbedrijven bekendstaan om hun hiërarchie en moordende werkschema’s, kiest DeepSeek voor een platte structuur die medewerkers autonomie geeft.
Impact op de Amerikaanse techgiganten
De schokgolven die door de industrie gaan, zijn enorm. Laten we dit eens per bedrijf bekijken:
OpenAI staat het meest onder druk. Als een concurrent binnen vier maanden je werk kan kopiëren – en goedkoper kan maken – hoe verdedigbaar is je positie dan? Ze hebben al defensieve maatregelen genomen door o3-mini gratis aan te bieden.
Microsoft en AWS zijn relatief model-agnostisch en focussen op infrastructuur. Goedkopere, efficiëntere modellen kunnen een brede adoptie juist versnellen. Microsoft-CEO Satya Nadella verwijst naar de paradox van Jevons: als iets goedkoper of efficiënter wordt, neemt het gebruik vaak explosief toe in plaats van dat het afvlakt.
Voor Apple zou dit juist goed nieuws kunnen zijn: hun focus op on-device AI past goed bij een opensourcemodel dat lokaal gedraaid kan worden. De markt lijkt dit ook in te zien: de waarde van Apple is met 3 procent gestegen.
NVIDIA wankelt
Voor NVIDIA lijkt de klap het hardst aan te komen. Hun explosief gestegen beurswaarde was gebouwd op één cruciale aanname: dat je voor AI-ontwikkeling de allernieuwste en snelste GPU’s nodig hebt.
Als de industrie zich realiseert dat topmodellen kunnen draaien op een fractie van de gebruikelijke kosten – en als die methoden open source en makkelijk te kopiëren zijn – wat betekent dat dan voor de vraag naar dure H100-chips? Dit verklaart waarom beleggers zo nerveus reageren op DeepSeeks doorbraak.
Toch is dit mogelijk een te simpele voorstelling van zaken. Pat Gelsinger, voormalig CEO van Intel, wijst op een historische constante: ‘Computing gehoorzaamt de gaswet – het vult de beschikbare ruimte zoals gedefinieerd door de middelen. Net als bij CMOS, pc’s, mobiel en talloze andere ontwikkelingen, zal het beschikbaar maken van rekenkracht tegen radicaal lagere prijzen leiden tot een explosieve uitbreiding van de markt.’
De toekomst van AI-ontwikkeling
Deze doorbraak markeert een belangrijk moment: de democratisering van geavanceerde AI. Ontwikkelaars kunnen nu de veeleisende, kapitaalintensieve stappen van modeltraining overslaan en voortbouwen op bestaande modellen.
‘In de laatste twee weken hebben AI-onderzoeksteams veel ambitieuzere ideeën gekregen over wat mogelijk is met minder kapitaal,’ merkt een insider op tegenover CNBC. ‘Voorheen dacht je aan een investering van honderden miljoenen dollars. DeepSeek laat zien wat je kunt bereiken met 10, 15 of 30 miljoen.’
Een genuanceerde blik op de toekomst
Toch moeten we voorzichtig zijn met overhaaste conclusies. Het feit dat DeepSeek met minder GPU’s kan concurreren met Amerikaanse labs betekent niet dat schaalwetten niet meer gelden. Zoals vooraanstaand AI-onderzoeker Andrej Karpathy het samenvat: ‘Betekent dit dat je geen grote GPU-clusters nodig hebt voor frontier AI-modellen? Nee, maar je moet er wel voor zorgen dat je niet verspillend omgaat met wat je hebt. Dit laat mooi zien dat er nog veel te winnen valt met zowel data als algoritmes.’
Wat we zien is geen revolutie die schaalwetten ontkracht, maar een demonstratie van wat mogelijk is met optimalisatie en incrementele innovatie. Het laat zien dat er meerdere paden zijn naar AI-vooruitgang: de Amerikaanse weg van massieve compute-kracht, en de Chinese weg van efficiëntie gedreven door beperkingen.
Net zoals de Spoetnik-lancering leidde tot een intensivering van de ruimterace, zal deze doorbraak de AI-ontwikkeling ongetwijfeld versnellen. Met één belangrijk verschil: waar de ruimterace werd gedreven door overheden, ligt de macht nu bij private bedrijven met de capaciteit van natiestaten.
Deze ontwikkeling dwingt ons fundamentele vragen te stellen. Is massieve rekenkracht echt de sleutel tot AI-vooruitgang, of zijn er slimmere wegen? Moet AI-ontwikkeling open of gesloten zijn? En belangrijker nog: hoe houden we controle over technologie die steeds autonomer wordt?
Eén ding is zeker: de AI-wereld is fundamenteel veranderd. Zoals Jack Clark, voormalig beleidshoofd bij OpenAI en medeoprichter van Anthropic het samenvat: ‘Chinese AI-modellen zullen net zo’n kracht worden om rekening mee te houden als drones en elektrische auto’s.’ De vraag is niet meer óf China kan concurreren, maar hoe deze nieuwe dynamiek de toekomst van AI zal vormgeven.
Ontgrendel de kracht van AI in je werk en je leven:
Upgrade naar ons betaalde abonnement en ontvang 2x per week game-changing AI-tools en tips.
Vandaag:
Hoe je DeepSeek offline op je laptop laat draaien
De beste instellingen voor optimale prestaties
Praktische tips voor dagelijks gebruik
BONUS: Maak professionele video’s met AI-avatars
Creëer sneller en goedkoper videocontent met AI
🛠️ AI Toolkit+
Zo draai je DeepSeek op je eigen computer
Net las je hoe DeepSeek de AI-wereld op zijn grondvesten doet schudden. Maar wat als je het model zelf wilt gebruiken, zonder je data te delen met servers in China of Amerika? Deze week laten we zien hoe dat kan.
Als bonus hebben we een verrassende ontdekking op het gebied van AI-contentcreatie voor je: een tool waarmee je levensechte AI-avatars maakt en complete video’s produceert.
Keep reading with a 7-day free trial
Subscribe to AI Report to keep reading this post and get 7 days of free access to the full post archives.